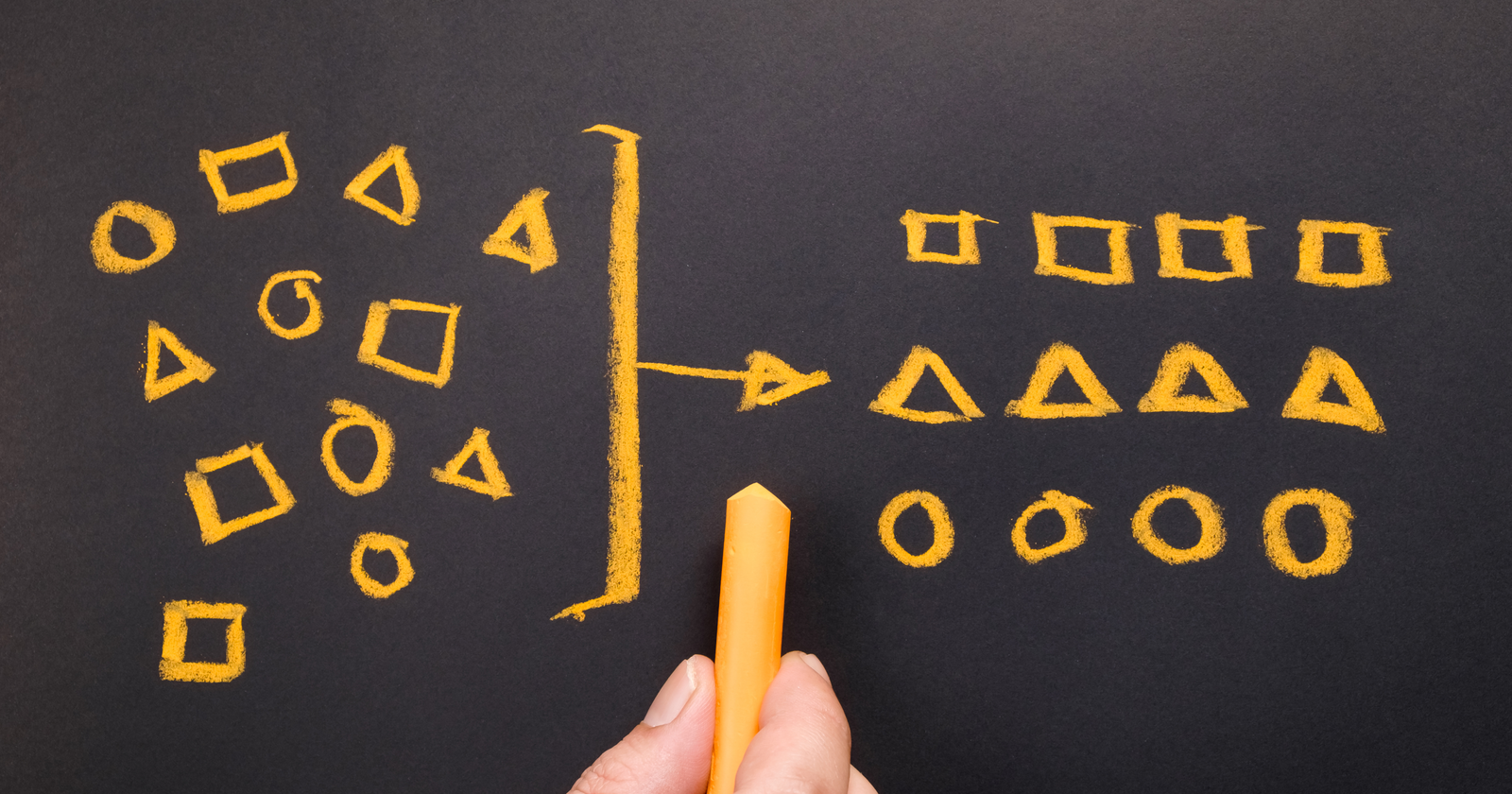
Clustering product inventory and automatically aligning SKUs to search demand is a great way to find opportunities to create new ecommerce categories.
Niche category pages are a proven way for ecommerce sites to align with organic search demand while simultaneously assisting users in purchasing.
If a site stocks a range of products and there is search demand, creating a dedicated landing page is an easy way to align with the demand.
But how can SEO professionals find this opportunity?
Sure, you can eyeball it, but you’ll usually leave a lot of opportunity on the table.
This problem motivated me to script something in Python, which I’m sharing today in a simple to use Streamlit application. (No coding experience required!)
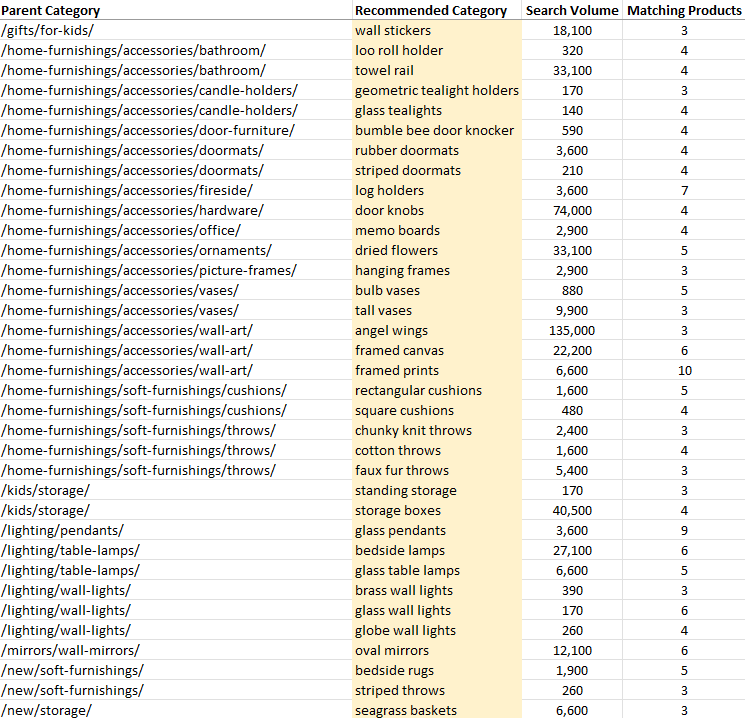
The app linked above created the following output automatically using nothing more than two crawl exports!
-
 Screenshot from Microsoft Excel, May 2022
Screenshot from Microsoft Excel, May 2022
Notice how the suggested categories are automatically tied back to the existing parent category?
-
 Screenshot from Microsoft Excel, May 2022
Screenshot from Microsoft Excel, May 2022
The app even shows how many products are available to populate the category.
-
 Screenshot from Microsoft Excel, May 2022
Screenshot from Microsoft Excel, May 2022
Benefits And Uses
- Improve relevancy to high-demand, competitive queries by creating new landing pages.
- Increase the chance of relevant site links displaying underneath the parent category.
- Reduce CPCs to the landing page through increased relevancy.
- Potential to inform merchandising decisions. (If there is high search demand vs. low product count – there is a potential to widen the range.0
-
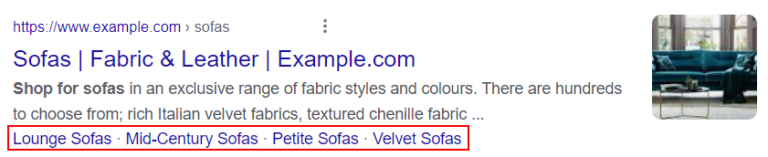 Mock-up Screenshot from Google Chrome, May 2022
Mock-up Screenshot from Google Chrome, May 2022
-
Creating the suggested subcategories for the parent sofa category would align the site to an additional 3,500 searches per month with relatively little effort.
Features
- Create subcategory suggestions automatically.
- Tie subcategories back to the parent category (cuts out a lot of guesswork!).
- Match to a minimum of X products before recommending a category.
- Check similarity to an existing category (X % fuzzy match) before recommending a new category.
- Set minimum search volume/CPC cut-off for category suggestions.
- Supports search volume and CPC data from multiple countries.
Getting Started/Prepping The Files
To use this app you need two things.
At a high level, the goal is to crawl the target website with two custom extractions.
The internal_html.csv report is exported, along with an inlinks.csv export.
These exports are then uploaded to the Streamlit app, where the opportunities are processed.
Crawl And Extraction Setup
When crawling the site, you’ll need to set two extractions in Screaming Frog – one to uniquely identify product pages and another to uniquely identify category pages.
The Streamlit app understands the difference between the two types of pages when making recommendations for new pages.
The trick is to find a unique element for each page type.
(For a product page, this is usually the price or the returns policy, and for a category page, it’s usually a filter sort element.)
Extracting The Unique Page Elements
Screaming Frog allows for custom extractions of content or code from a web page when crawled.
This section may be daunting if you are unfamiliar with custom extractions, but it’s essential for getting the correct data into the Streamlit app.
The goal is to end up with something looking like the below image.
(A unique extraction for product and category pages with no overlap.)
-
 Screenshot from Screaming Frog SEO Spider, May 2022
Screenshot from Screaming Frog SEO Spider, May 2022
The steps below walk you through manually extracting the price element for a product page.
Then, repeat for a category page afterward.
If you’re stuck or would like to read more about the web scraper tool in Screaming Frog, the official documentation is worth your time.
Manually Extracting Page Elements
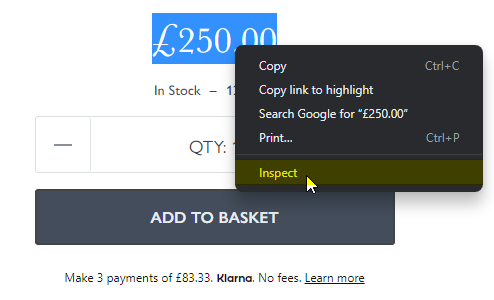
Let’s start by extracting a unique element only found on a product page (usually the price).
Highlight the price element on the page with the mouse, right-click and choose Inspect.
-
 Screenshot from Google Chrome, May 2022
Screenshot from Google Chrome, May 2022
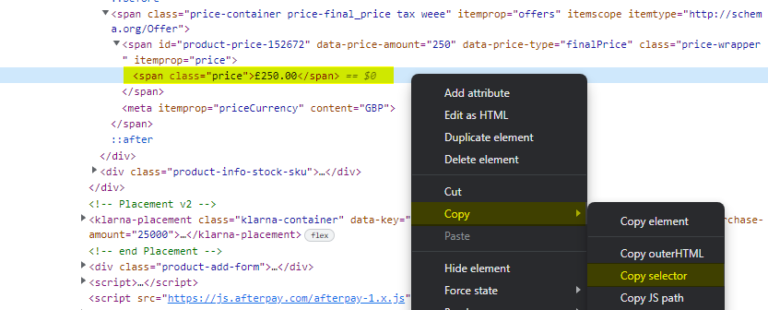
This will open up the elements window with the correct HTML line already selected.
Right-click the pre-selected line and choose Copy > Copy selector. That’s it!
-
 Screenshot from Google Chrome, May 2022
Screenshot from Google Chrome, May 2022
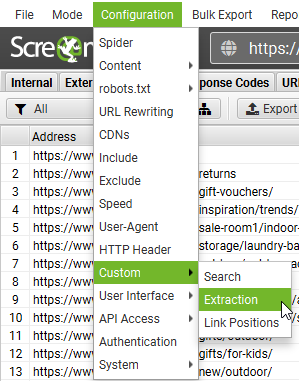
Open Screaming Frog and paste the copied selector into the custom extraction section. (Configuration > Custom > Extraction).
-
 Screenshot from Screaming Frog SEO Spider, May 2022
Screenshot from Screaming Frog SEO Spider, May 2022
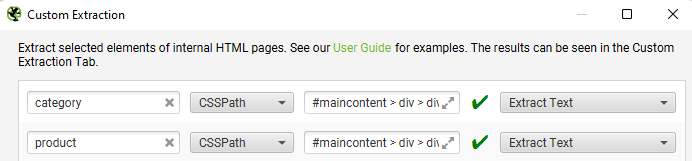
Name the extractor as “product,” select the CSSPath drop down and choose Extract Text.
Repeat the process to extract a unique element from a category page. It should look like this once completed for both product and category pages.
-
 Screenshot from Screaming Frog SEO Spider, May 2022
Screenshot from Screaming Frog SEO Spider, May 2022
Finally, start the crawl.
The crawl should look like this when viewing the Custom Extraction tab.
-
Screenshot from Screaming Frog SEO Spider, May 2022
Notice how the extractions are unique to each page type? Perfect.
The script uses the extractor to identify the page type.
Internally the app will convert the extractor to tags.
(I mention this to stress that the extractors can be anything as long as they uniquely identify both page types.)
-
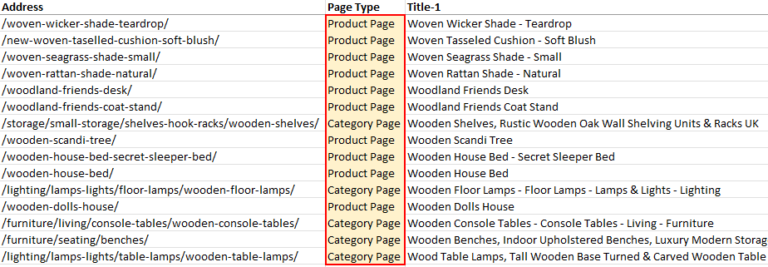 Screenshot from Microsoft Excel, May 2022
Screenshot from Microsoft Excel, May 2022
Exporting The Files
Once the crawl has been completed, the last step is to export two types of CSV files.
- internal_html.csv.
- inlinks to product pages.
Go to the Custom Extraction tab in Screaming Frog and highlight all URLs that have an extraction for products.
(You will need to sort the column to group it.)
-
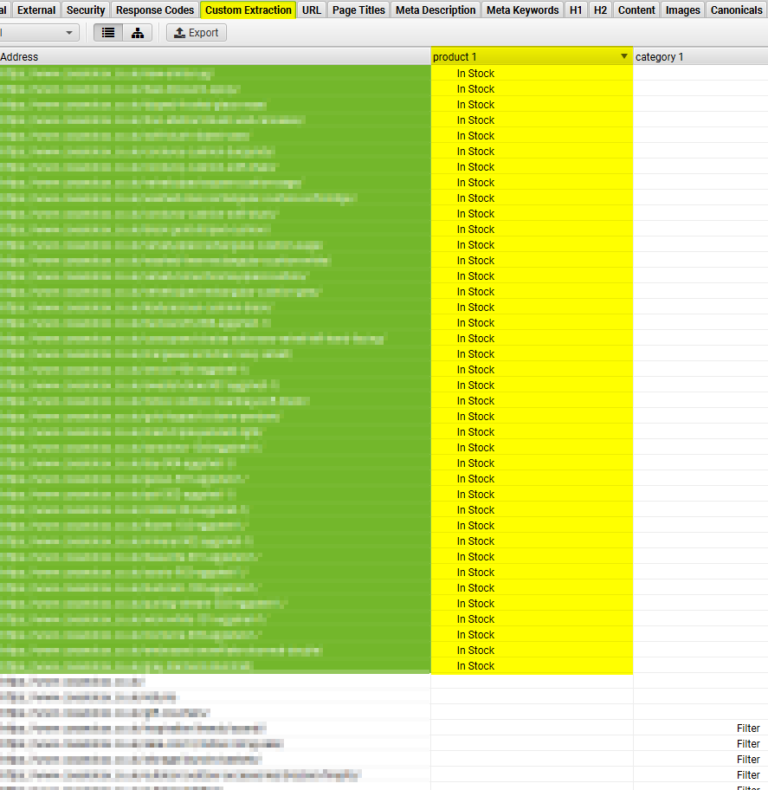 Screenshot from Screaming Frog SEO Spider, May 2022
Screenshot from Screaming Frog SEO Spider, May 2022
Lastly, right-click the product URLs, select Export, and then Inlinks.
-
 Screenshot from Screaming Frog SEO Spider, May 2022
Screenshot from Screaming Frog SEO Spider, May 2022
You should now have a file called inlinks.csv.
Finally, we just need to export the internal_html.csv file.
Click the Internal tab, select HTML from the dropdown menu below and click on the adjacent Export button.
Finally, choose the option to save the file as a .csv
-
 Screenshot from Screaming Frog SEO Spider, May 2022
Screenshot from Screaming Frog SEO Spider, May 2022
Congratulations! You are now ready to use the Streamlit app!
Using The Streamlit App
Using the Streamlit app is relatively simple.
The various options are set to reasonable defaults, but feel free to adjust the cut-offs to better suit your needs.
I would highly recommend using a Keywords Everywhere API key (although it is not strictly necessary as this can be looked up manually later with an existing tool if preferred.
(The script pre-qualifies opportunity by checking for search volume. If the key is missing, the final output will contain more irrelevant words.)
If you want to use a key, this is the section on the left to pay attention to.
-
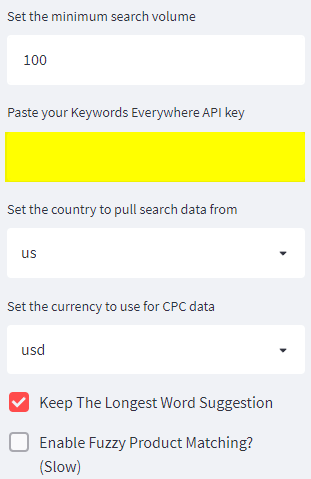 Screenshot from Streamlit.io, May 2022
Screenshot from Streamlit.io, May 2022
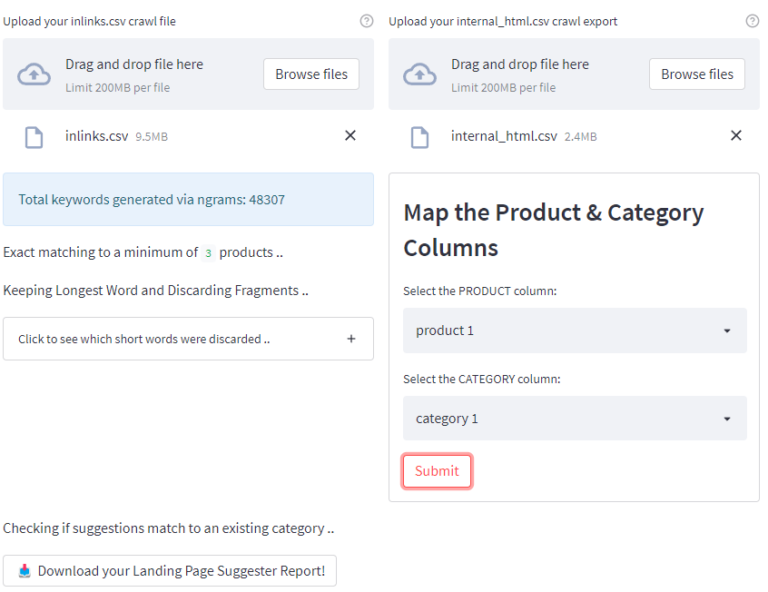
Once you have entered the API key and adjusted the cut-offs to your links, upload the inlinks.csv crawl.
-
 Screenshot from Streamlit.io, May 2022
Screenshot from Streamlit.io, May 2022
Once complete, a new prompt will appear adjacent to it, prompting you to upload the internal_html.csv crawl file.
-
 Screenshot from Streamlit.io, May 2022
Screenshot from Streamlit.io, May 2022
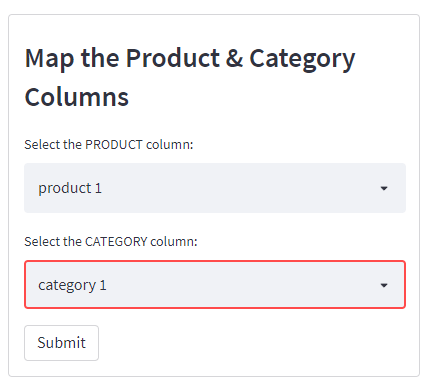
Finally, a new box will appear asking you to select the product and column names from the uploaded crawl file to be mapped correctly.
-
 Screenshot from Streamlit.io, May 2022
Screenshot from Streamlit.io, May 2022
Click submit and the script will run. Once complete, you will see the following screen and can download a handy .csv export.
-
 Screenshot from Streamlit.io, May 2022
Screenshot from Streamlit.io, May 2022
How The Script Works
Before we dive into the script’s output, it will help to explain what’s going on under the hood at a high level.
At a glance:
- Generate thousands of keywords by generating n-grams from product page H1 headings.
- Qualify keywords by checking whether the word is in an exact or fuzzy match in a product heading.
- Further qualify keywords by checking for search volume using the Keywords Everywhere API (optional but recommended).
- Check whether an existing category already exists using a fuzzy match (can find words out of order, different tenses, etc.).
- Uses the inlinks report to assign suggestions to a parent category automatically.
N-gram Generation
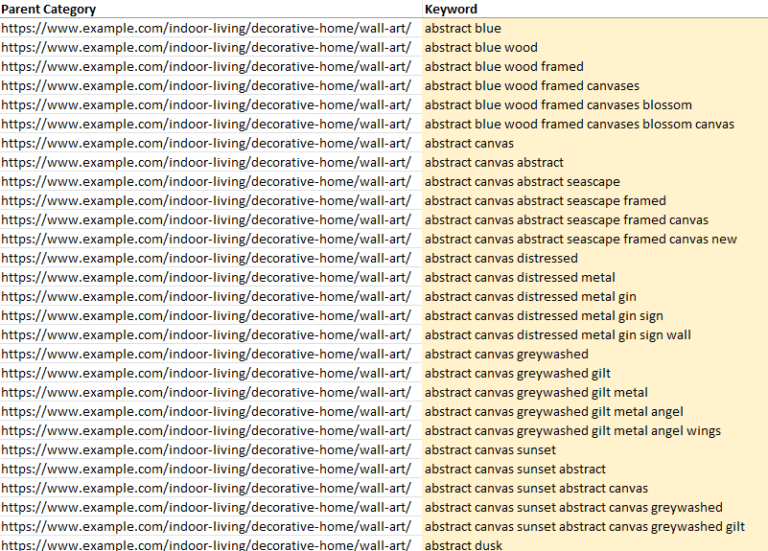
The script creates hundreds of thousands of n-grams from the product page H1s, most of which are completely nonsensical.
In my example for this article, n-grams generated 48,307 words – so this will need to be filtered!
-
 Screenshot from Microsoft Excel, May 2022
Screenshot from Microsoft Excel, May 2022
The first step in the filtering process is to check whether the keywords generated via n-grams are found at least X times within the product name column.
(This can be in an exact or fuzzy match.)
Anything not found is immediately discarded, which usually removes around 90% of the generated keywords.
The second filtering stage is to check whether the remaining keywords have search demand.
Any keywords without search demand are then discarded too.
(This is why I recommend using the Keywords Everywhere API when running the script, which results in a more refined output.)
It’s worth noting you can do this manually afterward by searching Semrush/Ahrefs etc., discarding any keywords without search volume, and running a VLOOKUP in Microsoft Excel.
Cheaper if you have an existing subscription.
Recommendations Tied To Specific Landing Pages
Once the keyword list has been filtered the script uses the inlinks report to tie the suggested subcategory back to the landing page.
Earlier versions did not do this, but I realized that leveraging the inlinks.csv report meant it was possible.
It really helps understand the context of the suggestion at a glance during QA.
This is the reason the script requires two exports to work correctly.
Limitations
- Not checking search volumes will result in more results for QA. (Even if you don’t use the Keywords Everywhere API, I recommend shortlisting by filtering out 0 search volume afterward.)
- Some irrelevant keywords will have search volume and appear in the final report, even if keyword volume has been checked.
- Words will typically appear in the singular sense for the final output (because products are singular and categories are pluralized if they sell more than a single product). It’s easy enough to add an “s” to the end of the suggestion though.
User Configurable Variables
I’ve selected what I consider to be sensible default options.
But here is a run down if you’d like to tweak and experiment.
- Minimum products to match to (exact match) – The minimum number of products that must exist before suggesting the new category in an exact match.
- Minimum products to match to (fuzzy match) – The minimum number of products that must exist before suggesting the new category in a fuzzy match, (words can be found in any order).
- Minimum similarity to an existing category – This checks whether a category already exists in a fuzzy match before making the recommendation. The closer to 100 = stricter matching.
- Minimum CPC in $ – The minimum dollar amount of the suggested category keyword. (Requires the Keywords Everywhere API.)
- Minimum search volume – The minimum search volume of the suggested category keyword. (Requires Keywords Everywhere API.)
- Keywords Everywhere API key – Optional, but recommended. Used to pull in CPC/search volume data. (Useful for shortlisting categories.)
- Set the country to pull search data from – Country-specific search data is available. (Default is the USA.)
- Set the currency for CPC data – Country-specific CPC data is available. (Default USD.)
- Keep the longest word suggestion – With similar word suggestions, this option will keep the longest match.
- Enable fuzzy product matching – This will search for product names in a fuzzy match. (Words can be found out of order, recommended – but slow and CPU intensive.)
Conclusion
With a small amount of preparation, it is possible to tap into a large amount of organic opportunity while improving the user experience.
Although this script was created with an ecommerce focus, according to feedback, it works well for other site types such as job listing sites.
So even if your site isn’t an ecommerce site, it’s still worth a try.
Python enthusiast?
I released the source code for a non-Streamlit version here.
More resources:
Featured Image: patpitchaya/Shutterstock