
In my last article, we analyzed our backlinks using data from Ahrefs.
This time around, we’re including the competitor backlinks in our analysis using the same Ahrefs data source for comparison.
Like last time, we defined the value of a site’s backlinks for SEO as a product of quality and quantity.
Quality is domain authority (or Ahrefs’ equivalent domain rating) and quantity is the number of referring domains.
Again, we’ll evaluate the link quality with the available data before evaluating the quantity.
Time to code.
import re
import time
import random
import pandas as pd
import numpy as np
import datetime
from datetime import timedelta
from plotnine import *
import matplotlib.pyplot as plt
from pandas.api.types import is_string_dtype
from pandas.api.types import is_numeric_dtype
import uritools
pd.set_option('display.max_colwidth', None)
%matplotlib inline
root_domain = 'johnsankey.co.uk' hostdomain = 'www.johnsankey.co.uk' hostname="johnsankey" full_domain = 'https://www.johnsankey.co.uk' target_name="John Sankey"
Data Import & Cleaning
We set up the file directories to read multiple Ahrefs exported data files in one folder, which is much faster, less boring, and more efficient than reading each file individually.
Especially when you have more than 10 of them!
ahrefs_path="data/"
The listdir( ) function from the OS module allows us to list all files in a subdirectory.
ahrefs_filenames = os.listdir(ahrefs_path)
ahrefs_filenames.remove('.DS_Store')
ahrefs_filenames
File names now listed below:
['www.davidsonlondon.com--refdomains-subdomain__2022-03-13_23-37-29.csv',
'www.stephenclasper.co.uk--refdomains-subdoma__2022-03-13_23-47-28.csv',
'www.touchedinteriors.co.uk--refdomains-subdo__2022-03-13_23-42-05.csv',
'www.lushinteriors.co--refdomains-subdomains__2022-03-13_23-44-34.csv',
'www.kassavello.com--refdomains-subdomains__2022-03-13_23-43-19.csv',
'www.tulipinterior.co.uk--refdomains-subdomai__2022-03-13_23-41-04.csv',
'www.tgosling.com--refdomains-subdomains__2022-03-13_23-38-44.csv',
'www.onlybespoke.com--refdomains-subdomains__2022-03-13_23-45-28.csv',
'www.williamgarvey.co.uk--refdomains-subdomai__2022-03-13_23-43-45.csv',
'www.hadleyrose.co.uk--refdomains-subdomains__2022-03-13_23-39-31.csv',
'www.davidlinley.com--refdomains-subdomains__2022-03-13_23-40-25.csv',
'johnsankey.co.uk-refdomains-subdomains__2022-03-18_15-15-47.csv']
With the files listed, we’ll now read each one individually using a for loop, and add these to a dataframe.
While reading in the file we’ll use some string manipulation to create a new column with the site name of the data we’re importing.
ahrefs_df_lst = list()
ahrefs_colnames = list()
for filename in ahrefs_filenames:
df = pd.read_csv(ahrefs_path + filename)
df['site'] = filename
df['site'] = df['site'].str.replace('www.', '', regex = False)
df['site'] = df['site'].str.replace('.csv', '', regex = False)
df['site'] = df['site'].str.replace('-.+', '', regex = True)
ahrefs_colnames.append(df.columns)
ahrefs_df_lst.append(df)
ahrefs_df_raw = pd.concat(ahrefs_df_lst)
ahrefs_df_raw
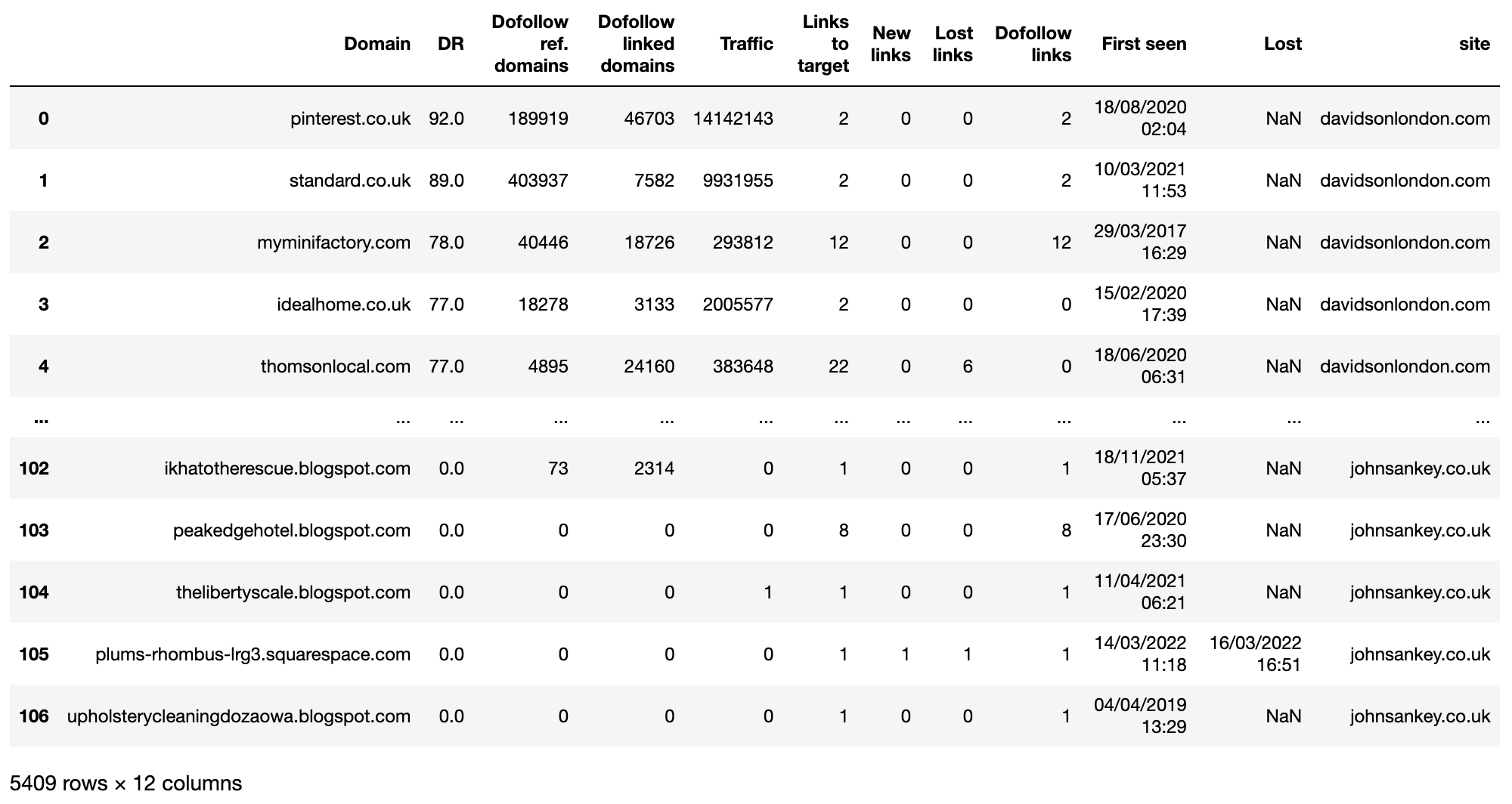
Image from Ahrefs, May 2022
Now we have the raw data from each site in a single dataframe. The next step is to tidy up the column names and make them a bit friendlier to work with.
Although the repetition could be eliminated with a custom function or a list comprehension, it is good practice and easier for beginner SEO Pythonistas to see what’s happening step by step. As they say, “repetition is the mother of mastery,” so get practicing!
competitor_ahrefs_cleancols = ahrefs_df_raw
competitor_ahrefs_cleancols.columns = [col.lower() for col in competitor_ahrefs_cleancols.columns]
competitor_ahrefs_cleancols.columns = [col.replace(' ','_') for col in competitor_ahrefs_cleancols.columns]
competitor_ahrefs_cleancols.columns = [col.replace('.','_') for col in competitor_ahrefs_cleancols.columns]
competitor_ahrefs_cleancols.columns = [col.replace('__','_') for col in competitor_ahrefs_cleancols.columns]
competitor_ahrefs_cleancols.columns = [col.replace('(','') for col in competitor_ahrefs_cleancols.columns]
competitor_ahrefs_cleancols.columns = [col.replace(')','') for col in competitor_ahrefs_cleancols.columns]
competitor_ahrefs_cleancols.columns = [col.replace('%','') for col in competitor_ahrefs_cleancols.columns]
The count column and having a single value column (‘project’) are useful for groupby and aggregation operations.
competitor_ahrefs_cleancols['rd_count'] = 1 competitor_ahrefs_cleancols['project'] = target_name competitor_ahrefs_cleancols
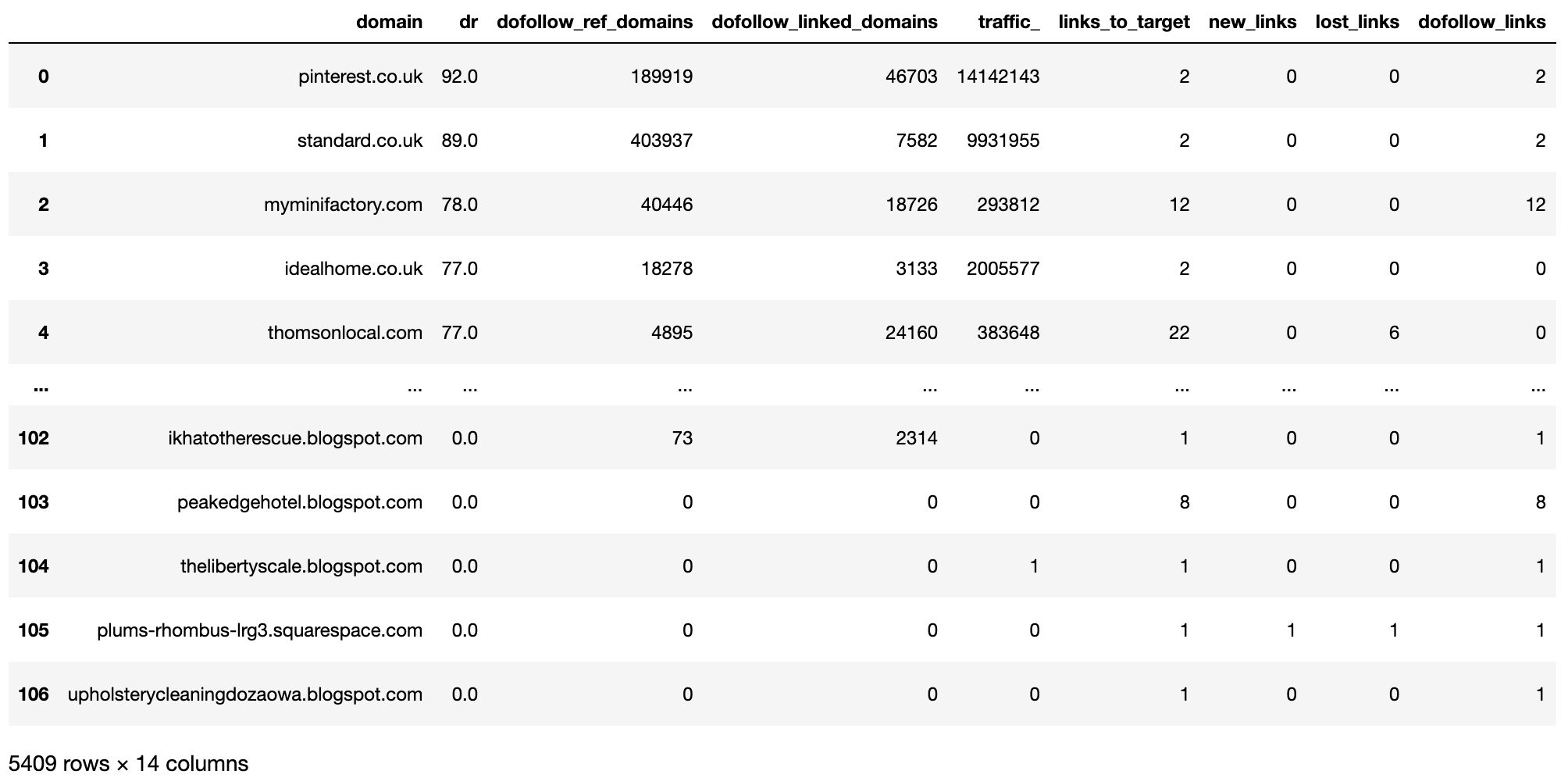 Image from Ahrefs, May 2022
Image from Ahrefs, May 2022The columns are cleaned up, so now we’ll clean up the row data.
competitor_ahrefs_clean_dtypes = competitor_ahrefs_cleancols
For referring domains, we’re replacing hyphens with zero and setting the data type as an integer (i.e., whole number).
This will be repeated for linked domains, also.
competitor_ahrefs_clean_dtypes['dofollow_ref_domains'] = np.where(competitor_ahrefs_clean_dtypes['dofollow_ref_domains'] == '-', 0, competitor_ahrefs_clean_dtypes['dofollow_ref_domains']) competitor_ahrefs_clean_dtypes['dofollow_ref_domains'] = competitor_ahrefs_clean_dtypes['dofollow_ref_domains'].astype(int) # linked_domains competitor_ahrefs_clean_dtypes['dofollow_linked_domains'] = np.where(competitor_ahrefs_clean_dtypes['dofollow_linked_domains'] == '-', 0, competitor_ahrefs_clean_dtypes['dofollow_linked_domains']) competitor_ahrefs_clean_dtypes['dofollow_linked_domains'] = competitor_ahrefs_clean_dtypes['dofollow_linked_domains'].astype(int)
First seen gives us a date point at which links were found, which we can use for time series plotting and deriving the link age.
We’ll convert to date format using the to_datetime function.
# first_seen
competitor_ahrefs_clean_dtypes['first_seen'] = pd.to_datetime(competitor_ahrefs_clean_dtypes['first_seen'],
format="%d/%m/%Y %H:%M")
competitor_ahrefs_clean_dtypes['first_seen'] = competitor_ahrefs_clean_dtypes['first_seen'].dt.normalize()
competitor_ahrefs_clean_dtypes['month_year'] = competitor_ahrefs_clean_dtypes['first_seen'].dt.to_period('M')
To calculate the link_age we’ll simply deduct the first seen date from today’s date and convert the difference into a number.
# link age competitor_ahrefs_clean_dtypes['link_age'] = dt.datetime.now() - competitor_ahrefs_clean_dtypes['first_seen'] competitor_ahrefs_clean_dtypes['link_age'] = competitor_ahrefs_clean_dtypes['link_age'] competitor_ahrefs_clean_dtypes['link_age'] = competitor_ahrefs_clean_dtypes['link_age'].astype(int) competitor_ahrefs_clean_dtypes['link_age'] = (competitor_ahrefs_clean_dtypes['link_age']/(3600 * 24 * 1000000000)).round(0)
The target column helps us distinguish the “client” site vs competitors which is useful for visualization later.
competitor_ahrefs_clean_dtypes['target'] = np.where(competitor_ahrefs_clean_dtypes['site'].str.contains('johns'),
1, 0)
competitor_ahrefs_clean_dtypes['target'] = competitor_ahrefs_clean_dtypes['target'].astype('category')
competitor_ahrefs_clean_dtypes
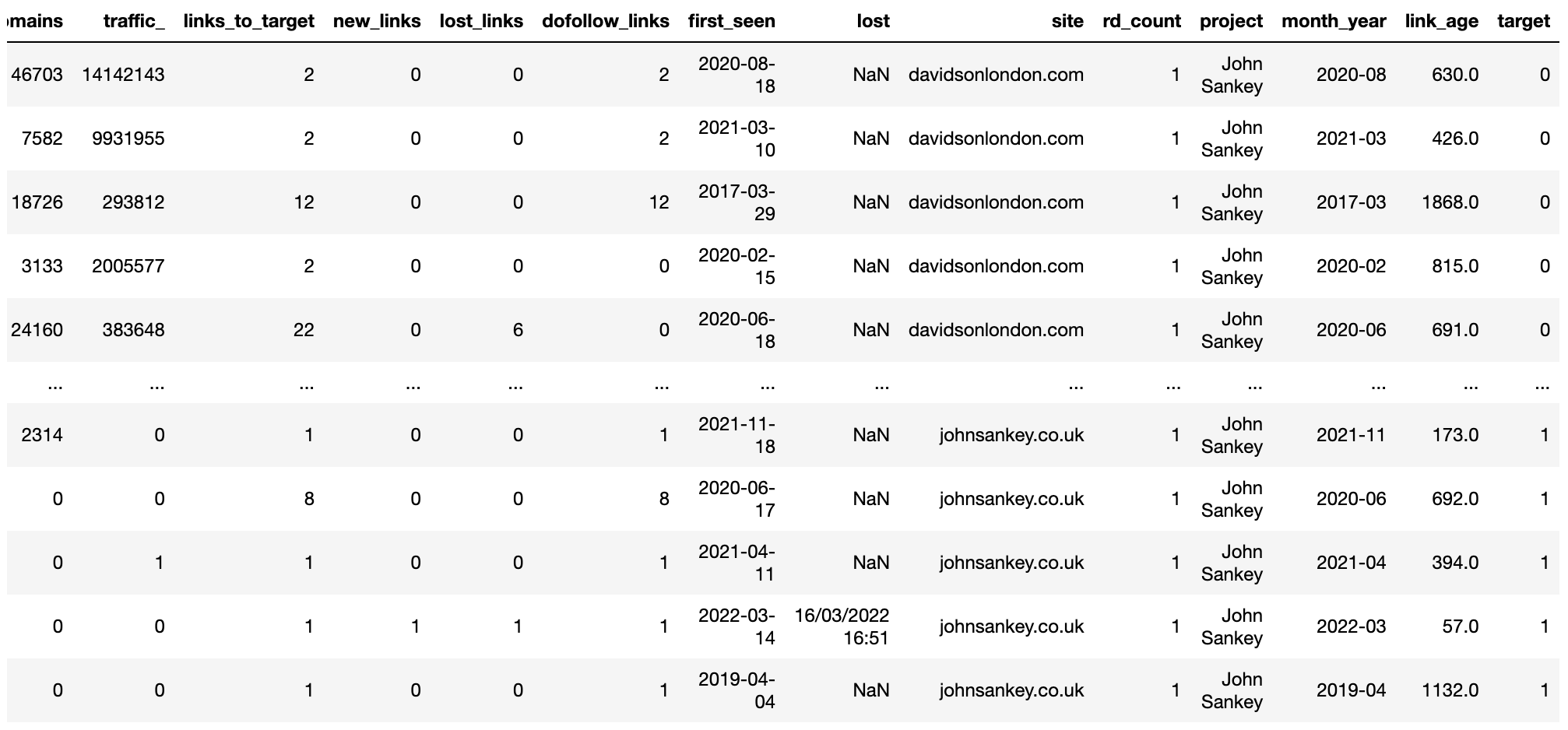 Image from Ahrefs, May 2022
Image from Ahrefs, May 2022Now that the data is cleaned up both in terms of column titles and row values we’re ready to set forth and start analyzing.
Link Quality
We start with Link Quality which we’ll accept Domain Rating (DR) as the measure.
Let’s start by inspecting the distributive properties of DR by plotting their distribution using the geom_bokplot function.
comp_dr_dist_box_plt = ( ggplot(competitor_ahrefs_analysis.loc[competitor_ahrefs_analysis['dr'] > 0], aes(x = 'reorder(site, dr)', y = 'dr', colour="target")) + geom_boxplot(alpha = 0.6) + scale_y_continuous() + theme(legend_position = 'none', axis_text_x=element_text(rotation=90, hjust=1) )) comp_dr_dist_box_plt.save(filename="images/4_comp_dr_dist_box_plt.png", height=5, width=10, units="in", dpi=1000) comp_dr_dist_box_plt
 Image from Ahrefs, May 2022
Image from Ahrefs, May 2022The plot compares the site’s statistical properties side by side, and most notably, the interquartile range showing where most referring domains fall in terms of domain rating.
We also see that John Sankey has the fourth-highest median domain rating, which compares well with link quality against other sites.
William Garvey has the most diverse range of DR compared with other domains, indicating ever so slightly more relaxed criteria for link acquisition. Who knows.
Link Volumes
That’s quality. What about the volume of links from referring domains?
To tackle that, we’ll compute a running sum of referring domains using the groupby function.
competitor_count_cumsum_df = competitor_ahrefs_analysis competitor_count_cumsum_df = competitor_count_cumsum_df.groupby(['site', 'month_year'])['rd_count'].sum().reset_index()
The expanding function allows the calculation window to grow with the number of rows which is how we achieve our running sum.
competitor_count_cumsum_df['count_runsum'] = competitor_count_cumsum_df['rd_count'].expanding().sum() competitor_count_cumsum_df
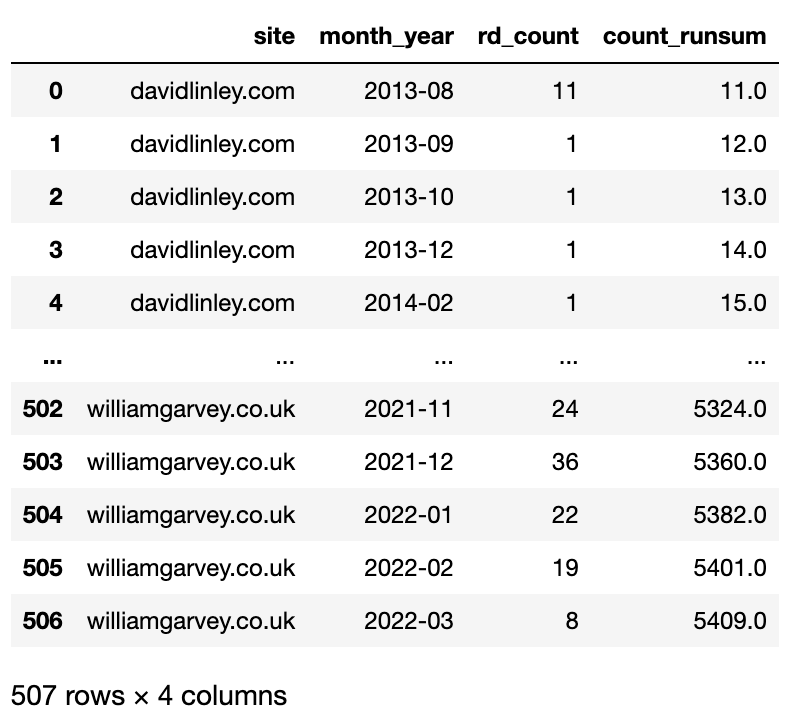 Image from Ahrefs, May 2022
Image from Ahrefs, May 2022The result is a data frame with the site, month_year and count_runsum (the running sum), which is in the perfect format to feed the graph.
competitor_count_cumsum_plt = ( ggplot(competitor_count_cumsum_df, aes(x = 'month_year', y = 'count_runsum', group = 'site', colour="site")) + geom_line(alpha = 0.6, size = 2) + labs(y = 'Running Sum of Referring Domains', x = 'Month Year') + scale_y_continuous() + scale_x_date() + theme(legend_position = 'right', axis_text_x=element_text(rotation=90, hjust=1) ))
competitor_count_cumsum_plt.save(filename="images/5_count_cumsum_smooth_plt.png", height=5, width=10, units="in", dpi=1000) competitor_count_cumsum_plt
 Image from Ahrefs, May 2022
Image from Ahrefs, May 2022The plot shows the number of referring domains for each site since 2014.
I find quite interesting the different starting positions for each site when they start acquiring links.
For example, William Garvey started with over 5,000 domains. I’d love to know who their PR agency is!
We can also see the rate of growth. For example, although Hadley Rose started link acquisition in 2018, things really took off around mid-2021.
More, More, And More
You can always do more scientific analysis.
For example, one immediate and natural extension of the above would be to combine both the quality (DR) and the quantity (volume) for a more holistic view of how the sites compare in terms of offsite SEO.
Other extensions would be to model the qualities of those referring domains for both your own and your competitor sites to see which link features (such as the number of words or relevance of the linking content) could explain the difference in visibility between you and your competitors.
This model extension would be a good application of these machine learning techniques.
More resources:
Featured Image: F8 studio/Shutterstock