
In a recent LinkedIn post, Gary Illyes, Analyst at Google, highlights lesser-known aspects of the robots.txt file as it marks its 30th year.
The robots.txt file, a web crawling and indexing component, has been a mainstay of SEO practices since its inception.
Here’s one of the reasons why it remains useful.
Robust Error Handling
Illyes emphasized the file’s resilience to errors.
“robots.txt is virtually error free,” Illyes stated.
In his post, he explained that robots.txt parsers are designed to ignore most mistakes without compromising functionality.
This means the file will continue operating even if you accidentally include unrelated content or misspell directives.
He elaborated that parsers typically recognize and process key directives such as user-agent, allow, and disallow while overlooking unrecognized content.
Unexpected Feature: Line Commands
Illyes pointed out the presence of line comments in robots.txt files, a feature he found puzzling given the file’s error-tolerant nature.
He invited the SEO community to speculate on the reasons behind this inclusion.
Responses To Illyes’ Post
The SEO community’s response to Illyes’ post provides additional context on the practical implications of robots.txt’s error tolerance and the use of line comments.
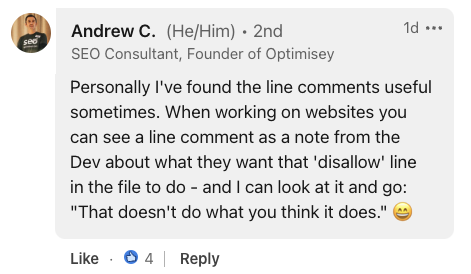
Andrew C., Founder of Optimisey, highlighted the utility of line comments for internal communication, stating:
“When working on websites you can see a line comment as a note from the Dev about what they want that ‘disallow’ line in the file to do.”
 Screenshot from LinkedIn, July 2024.
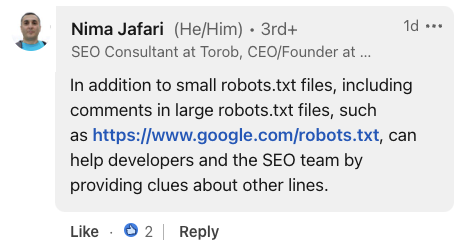
Screenshot from LinkedIn, July 2024.Nima Jafari, an SEO Consultant, emphasized the value of comments in large-scale implementations.
He noted that for extensive robots.txt files, comments can “help developers and the SEO team by providing clues about other lines.”
 Screenshot from LinkedIn, July 2024.
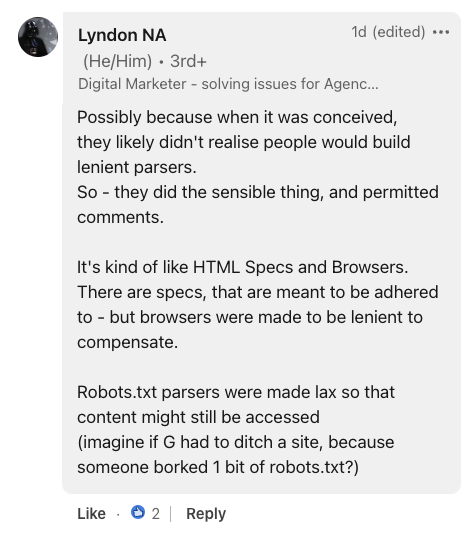
Screenshot from LinkedIn, July 2024.Providing historical context, Lyndon NA, a digital marketer, compared robots.txt to HTML specifications and browsers.
He suggested that the file’s error tolerance was likely an intentional design choice, stating:
“Robots.txt parsers were made lax so that content might still be accessed (imagine if G had to ditch a site, because someone borked 1 bit of robots.txt?).”
 Screenshot from LinkedIn, July 2024.
Screenshot from LinkedIn, July 2024.Why SEJ Cares
Understanding the nuances of the robots.txt file can help you optimize sites better.
While the file’s error-tolerant nature is generally beneficial, it could potentially lead to overlooked issues if not managed carefully.
What To Do With This Information
- Review your robots.txt file: Ensure it contains only necessary directives and is free from potential errors or misconfigurations.
- Be cautious with spelling: While parsers may ignore misspellings, this could result in unintended crawling behaviors.
- Leverage line comments: Comments can be used to document your robots.txt file for future reference.
Featured Image: sutadism/Shutterstock