
The concept of Compressibility as a quality signal is not widely known, but SEOs should be aware of it. Search engines can use web page compressibility to identify duplicate pages, doorway pages with similar content, and pages with repetitive keywords, making it useful knowledge for SEO.
Although the following research paper demonstrates a successful use of on-page features for detecting spam, the deliberate lack of transparency by search engines makes it difficult to say with certainty if search engines are applying this or similar techniques.
What Is Compressibility?
In computing, compressibility refers to how much a file (data) can be reduced in size while retaining essential information, typically to maximize storage space or to allow more data to be transmitted over the Internet.
TL/DR Of Compression
Compression replaces repeated words and phrases with shorter references, reducing the file size by significant margins. Search engines typically compress indexed web pages to maximize storage space, reduce bandwidth, and improve retrieval speed, among other reasons.
This is a simplified explanation of how compression works:
- Identify Patterns:
A compression algorithm scans the text to find repeated words, patterns and phrases - Shorter Codes Take Up Less Space:
The codes and symbols use less storage space then the original words and phrases, which results in a smaller file size. - Shorter References Use Less Bits:
The “code” that essentially symbolizes the replaced words and phrases uses less data than the originals.
A bonus effect of using compression is that it can also be used to identify duplicate pages, doorway pages with similar content, and pages with repetitive keywords.
Research Paper About Detecting Spam
This research paper is significant because it was authored by distinguished computer scientists known for breakthroughs in AI, distributed computing, information retrieval, and other fields.
Marc Najork
One of the co-authors of the research paper is Marc Najork, a prominent research scientist who currently holds the title of Distinguished Research Scientist at Google DeepMind. He’s a co-author of the papers for TW-BERT, has contributed research for increasing the accuracy of using implicit user feedback like clicks, and worked on creating improved AI-based information retrieval (DSI++: Updating Transformer Memory with New Documents), among many other major breakthroughs in information retrieval.
Dennis Fetterly
Another of the co-authors is Dennis Fetterly, currently a software engineer at Google. He is listed as a co-inventor in a patent for a ranking algorithm that uses links, and is known for his research in distributed computing and information retrieval.
Those are just two of the distinguished researchers listed as co-authors of the 2006 Microsoft research paper about identifying spam through on-page content features. Among the several on-page content features the research paper analyzes is compressibility, which they discovered can be used as a classifier for indicating that a web page is spammy.
Detecting Spam Web Pages Through Content Analysis
Although the research paper was authored in 2006, its findings remain relevant to today.
Then, as now, people attempted to rank hundreds or thousands of location-based web pages that were essentially duplicate content aside from city, region, or state names. Then, as now, SEOs often created web pages for search engines by excessively repeating keywords within titles, meta descriptions, headings, internal anchor text, and within the content to improve rankings.
Section 4.6 of the research paper explains:
“Some search engines give higher weight to pages containing the query keywords several times. For example, for a given query term, a page that contains it ten times may be higher ranked than a page that contains it only once. To take advantage of such engines, some spam pages replicate their content several times in an attempt to rank higher.”
The research paper explains that search engines compress web pages and use the compressed version to reference the original web page. They note that excessive amounts of redundant words results in a higher level of compressibility. So they set about testing if there’s a correlation between a high level of compressibility and spam.
They write:
“Our approach in this section to locating redundant content within a page is to compress the page; to save space and disk time, search engines often compress web pages after indexing them, but before adding them to a page cache.
…We measure the redundancy of web pages by the compression ratio, the size of the uncompressed page divided by the size of the compressed page. We used GZIP …to compress pages, a fast and effective compression algorithm.”
High Compressibility Correlates To Spam
The results of the research showed that web pages with at least a compression ratio of 4.0 tended to be low quality web pages, spam. However, the highest rates of compressibility became less consistent because there were fewer data points, making it harder to interpret.
Figure 9: Prevalence of spam relative to compressibility of page.
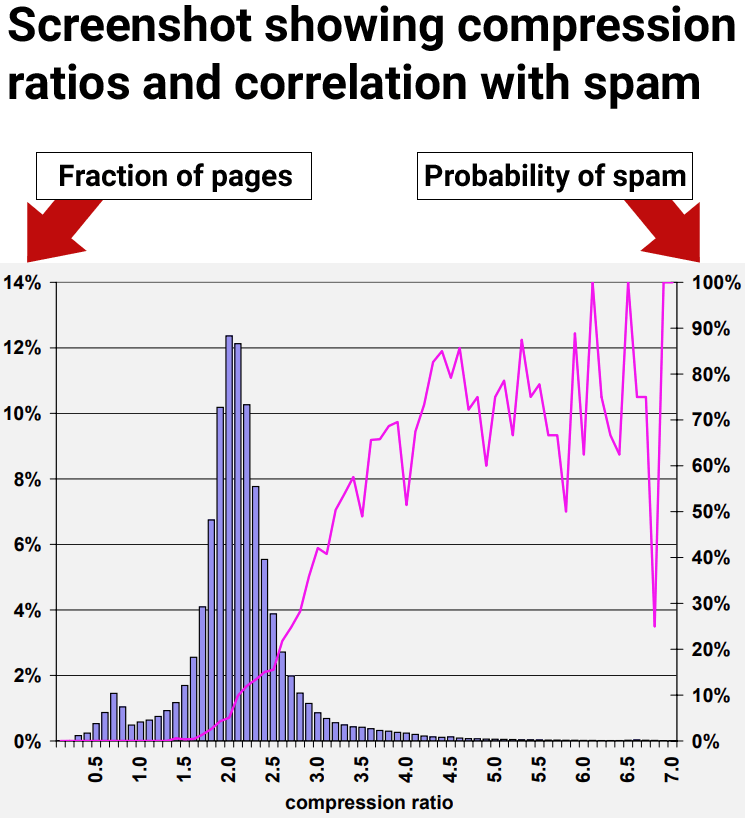
The researchers concluded:
“70% of all sampled pages with a compression ratio of at least 4.0 were judged to be spam.”
But they also discovered that using the compression ratio by itself still resulted in false positives, where non-spam pages were incorrectly identified as spam:
“The compression ratio heuristic described in Section 4.6 fared best, correctly identifying 660 (27.9%) of the spam pages in our collection, while misidentifying 2, 068 (12.0%) of all judged pages.
Using all of the aforementioned features, the classification accuracy after the ten-fold cross validation process is encouraging:
95.4% of our judged pages were classified correctly, while 4.6% were classified incorrectly.
More specifically, for the spam class 1, 940 out of the 2, 364 pages, were classified correctly. For the non-spam class, 14, 440 out of the 14,804 pages were classified correctly. Consequently, 788 pages were classified incorrectly.”
The next section describes an interesting discovery about how to increase the accuracy of using on-page signals for identifying spam.
Insight Into Quality Rankings
The research paper examined multiple on-page signals, including compressibility. They discovered that each individual signal (classifier) was able to find some spam but that relying on any one signal on its own resulted in flagging non-spam pages for spam, which are commonly referred to as false positive.
The researchers made an important discovery that everyone interested in SEO should know, which is that using multiple classifiers increased the accuracy of detecting spam and decreased the likelihood of false positives. Just as important, the compressibility signal only identifies one kind of spam but not the full range of spam.
The takeaway is that compressibility is a good way to identify one kind of spam but there are other kinds of spam that aren’t caught with this one signal. Other kinds of spam were not caught with the compressibility signal.
This is the part that every SEO and publisher should be aware of:
“In the previous section, we presented a number of heuristics for assaying spam web pages. That is, we measured several characteristics of web pages, and found ranges of those characteristics which correlated with a page being spam. Nevertheless, when used individually, no technique uncovers most of the spam in our data set without flagging many non-spam pages as spam.
For example, considering the compression ratio heuristic described in Section 4.6, one of our most promising methods, the average probability of spam for ratios of 4.2 and higher is 72%. But only about 1.5% of all pages fall in this range. This number is far below the 13.8% of spam pages that we identified in our data set.”
So, even though compressibility was one of the better signals for identifying spam, it still was unable to uncover the full range of spam within the dataset the researchers used to test the signals.
Combining Multiple Signals
The above results indicated that individual signals of low quality are less accurate. So they tested using multiple signals. What they discovered was that combining multiple on-page signals for detecting spam resulted in a better accuracy rate with less pages misclassified as spam.
The researchers explained that they tested the use of multiple signals:
“One way of combining our heuristic methods is to view the spam detection problem as a classification problem. In this case, we want to create a classification model (or classifier) which, given a web page, will use the page’s features jointly in order to (correctly, we hope) classify it in one of two classes: spam and non-spam.”
These are their conclusions about using multiple signals:
“We have studied various aspects of content-based spam on the web using a real-world data set from the MSNSearch crawler. We have presented a number of heuristic methods for detecting content based spam. Some of our spam detection methods are more effective than others, however when used in isolation our methods may not identify all of the spam pages. For this reason, we combined our spam-detection methods to create a highly accurate C4.5 classifier. Our classifier can correctly identify 86.2% of all spam pages, while flagging very few legitimate pages as spam.”
Key Insight:
Misidentifying “very few legitimate pages as spam” was a significant breakthrough. The important insight that everyone involved with SEO should take away from this is that one signal by itself can result in false positives. Using multiple signals increases the accuracy.
What this means is that SEO tests of isolated ranking or quality signals will not yield reliable results that can be trusted for making strategy or business decisions.
Takeaways
We don’t know for certain if compressibility is used at the search engines but it’s an easy to use signal that combined with others could be used to catch simple kinds of spam like thousands of city name doorway pages with similar content. Yet even if the search engines don’t use this signal, it does show how easy it is to catch that kind of search engine manipulation and that it’s something search engines are well able to handle today.
Here are the key points of this article to keep in mind:
- Doorway pages with duplicate content is easy to catch because they compress at a higher ratio than normal web pages.
- Groups of web pages with a compression ratio above 4.0 were predominantly spam.
- Negative quality signals used by themselves to catch spam can lead to false positives.
- In this particular test, they discovered that on-page negative quality signals only catch specific types of spam.
- When used alone, the compressibility signal only catches redundancy-type spam, fails to detect other forms of spam, and leads to false positives.
- Combing quality signals improves spam detection accuracy and reduces false positives.
- Search engines today have a higher accuracy of spam detection with the use of AI like Spam Brain.
Read the research paper, which is linked from the Google Scholar page of Marc Najork:
Detecting spam web pages through content analysis
Featured Image by Shutterstock/pathdoc