
For SEO experts, Google’s core updates are a way of life. They will happen at least once – if not multiple times – a year.
Naturally, there will be winners and losers.
So while Google doesn’t disclose most of the ranking factors behind the algorithm updates, there are things we can do to get a greater understanding of what’s going on, in terms of:
- Which site content is affected.
- Sites operating in your search space.
- Result types.
The limit is your imagination, your questions (based on your SEO knowledge), and of course, your data.
This code will cover aggregations at the search engine results page (SERP) level (inter-site category comparison), and the same principles can be applied to other views of the core update such as result types (think snippets and other views mentioned above).
Using Python To Compare SERPs
The overall principle is to compare the SERPs before and after the core update, which will give us some clues as to what’s going on.
We’ll start by importing our Python libraries:
import re
import time
import random
import pandas as pd
import numpy as np
import datetime
from datetime import timedelta
from plotnine import *
import matplotlib.pyplot as plt
from pandas.api.types import is_string_dtype
from pandas.api.types import is_numeric_dtype
import uritools
pd.set_option('display.max_colwidth', None)
%matplotlib inline
Defining some variables, we’re going to be focusing on ON24.com as they lost out to the core update.
root_domain = 'on24.com' hostdomain = 'www.on24.com' hostname="on24" full_domain = 'https://www.on24.com' site_name="ON24"
Reading in the data, we’re using an export from GetSTAT which has a useful report that allows you to compare SERPs for your keywords before and after.
This SERPs report is available from other rank tracking providers like SEO Monitor and Advanced Web Ranking – no preferences or endorsements on my side!
getstat_ba_urls = pd.read_csv('data/webinars_top_20.csv', encoding = 'UTF-16', sep = 't')
getstat_raw.head()
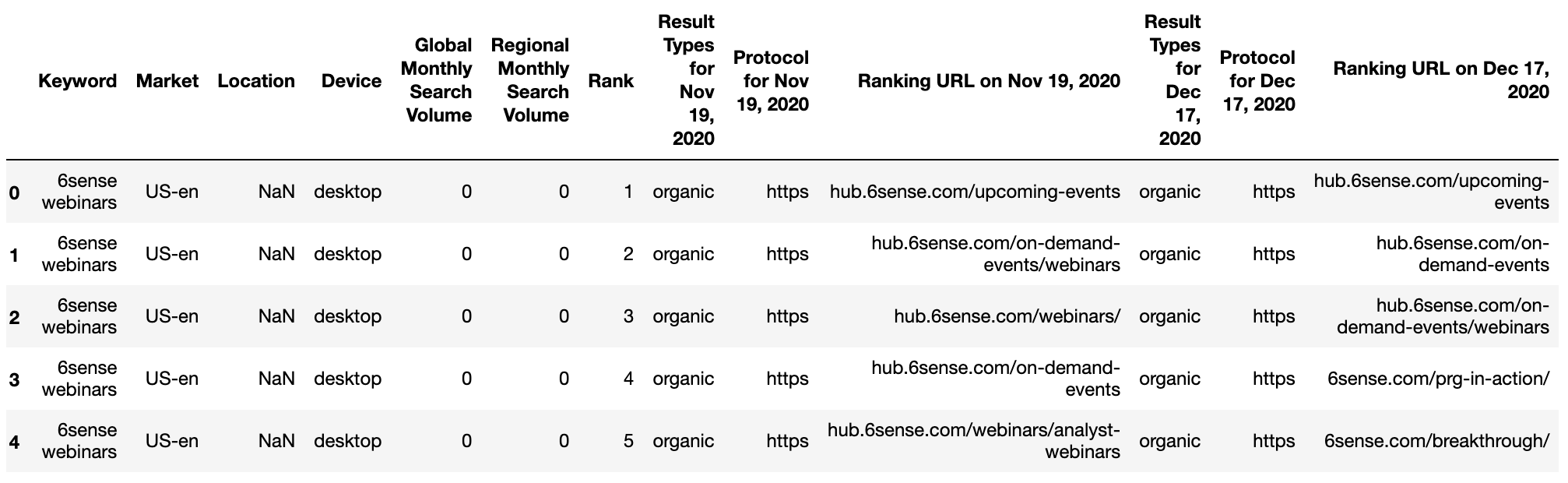 Screenshot by author, January 2022
Screenshot by author, January 2022getstat_ba_urls = getstat_raw
Construct the URLs by joining the protocol and URL string to get the full ranking URL for both before the update and after.
getstat_ba_urls['before_url'] = getstat_ba_urls['Protocol for Nov 19, 2020'] + '://' + getstat_ba_urls['Ranking URL on Nov 19, 2020'] getstat_ba_urls['after_url'] = getstat_ba_urls['Protocol for Dec 17, 2020'] + '://' + getstat_ba_urls['Ranking URL on Dec 17, 2020'] getstat_ba_urls['before_url'] = np.where(getstat_ba_urls['before_url'].isnull(), '', getstat_ba_urls['before_url']) getstat_ba_urls['after_url'] = np.where(getstat_ba_urls['after_url'].isnull(), '', getstat_ba_urls['after_url'])
To get the domains of the ranking URLs, we create a copy of the URL in a new column, remove the subdomains using an if statement embedded in a list comprehension:
getstat_ba_urls['before_site'] = [uritools.urisplit(x).authority if uritools.isuri(x) else x for x in getstat_ba_urls['before_url']]
stop_sites = ['hub.', 'blog.', 'www.', 'impact.', 'harvard.', 'its.', 'is.', 'support.']
getstat_ba_urls['before_site'] = getstat_ba_urls['before_site'].str.replace('|'.join(stop_sites), '')
The list comprehension is repeated to extract the domains post update.
getstat_ba_urls['after_site'] = [uritools.urisplit(x).authority if uritools.isuri(x) else x for x in getstat_ba_urls['after_url']]
getstat_ba_urls['after_site'] = getstat_ba_urls['after_site'].str.replace('|'.join(stop_sites), '')
getstat_ba_urls.columns = [x.lower() for x in getstat_ba_urls.columns]
getstat_ba_urls = getstat_ba_urls.rename(columns = {'global monthly search volume': 'search_volume'
})
getstat_ba_urls
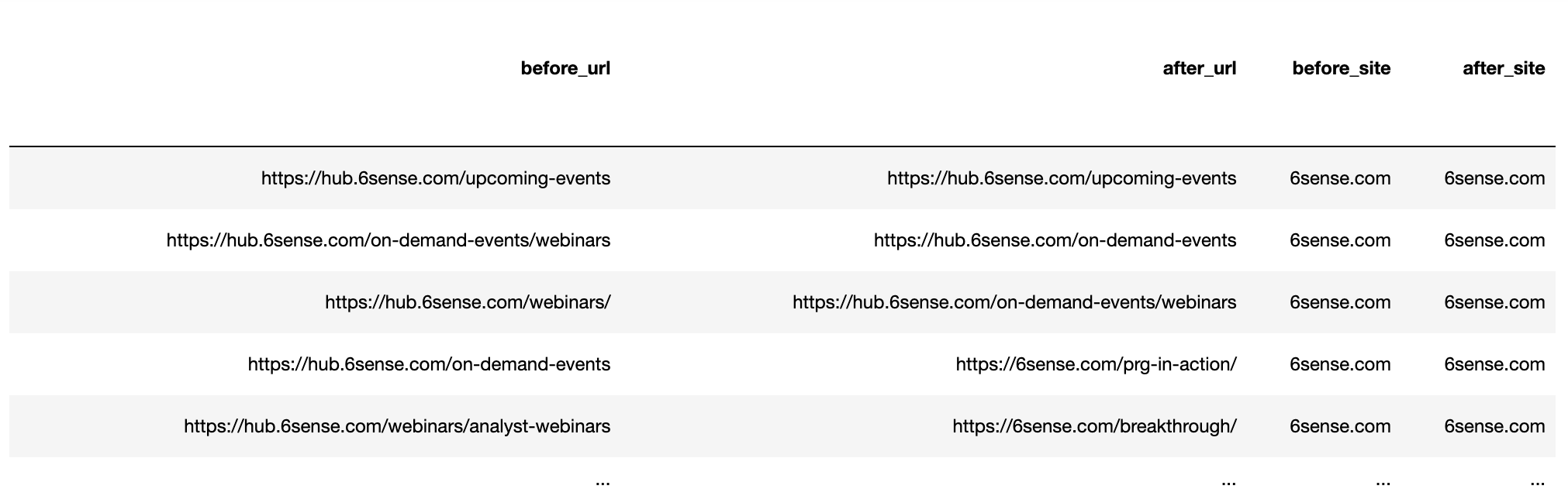 Screenshot by author, January 2022
Screenshot by author, January 2022Dedupe Multiple Ranking URLs
The next step is to remove the multiple ranking URLs by the same domain per keyword SERP. We’ll split the data into two sets, before and after.
Then we’ll group by keyword and perform the deduplication:
getstat_bef_unique = getstat_ba_urls[['keyword', 'market', 'location', 'device', 'search_volume', 'rank',
'result types for nov 19, 2020', 'protocol for nov 19, 2020',
'ranking url on nov 19, 2020', 'before_url', 'before_site']]
getstat_bef_unique = getstat_bef_unique.sort_values('rank').groupby(['before_site', 'device', 'keyword']).first()
getstat_bef_unique = getstat_bef_unique.reset_index()
getstat_bef_unique = getstat_bef_unique[getstat_bef_unique['before_site'] != '']
getstat_bef_unique = getstat_bef_unique.sort_values(['keyword', 'device', 'rank'])
getstat_bef_unique = getstat_bef_unique.rename(columns = {'rank': 'before_rank',
'result types for nov 19, 2020': 'before_snippets'})
getstat_bef_unique = getstat_bef_unique[['keyword', 'market', 'device', 'before_snippets', 'search_volume',
'before_url', 'before_site', 'before_rank'
]]
getstat_bef_unique
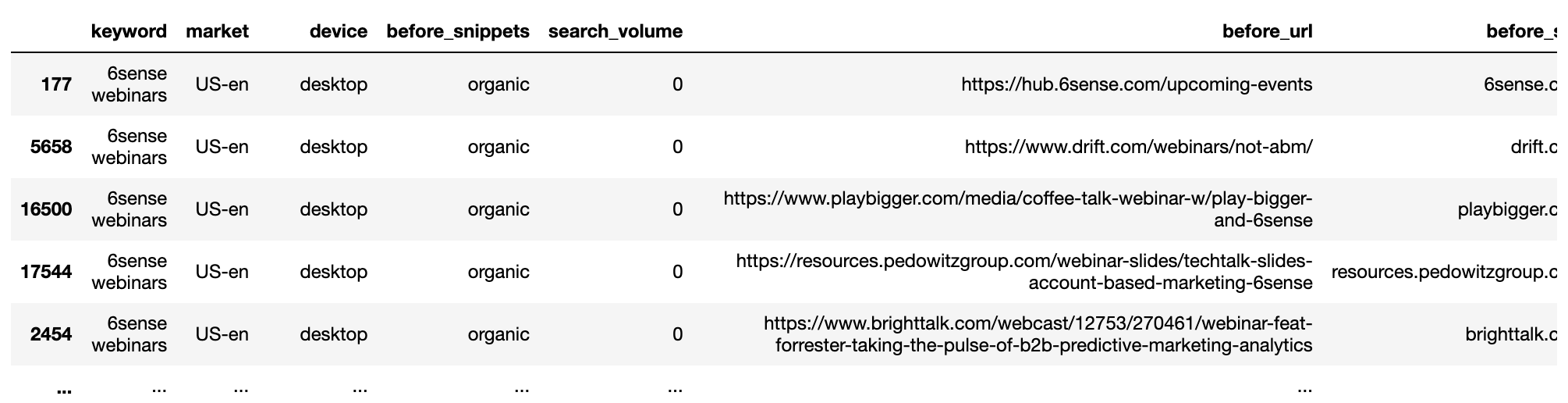 Screenshot by author, January 2022
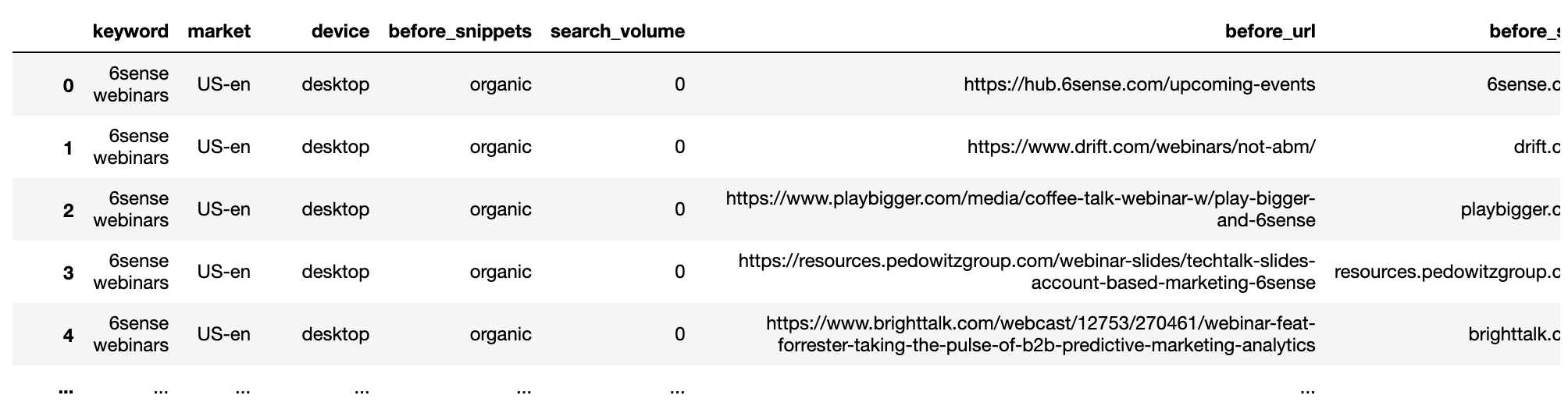
Screenshot by author, January 2022The procedure is repeated for the after data set.
getstat_aft_unique = getstat_ba_urls[['keyword', 'market', 'location', 'device', 'search_volume', 'rank',
'result types for dec 17, 2020', 'protocol for dec 17, 2020',
'ranking url on dec 17, 2020', 'after_url', 'after_site']]
getstat_aft_unique = getstat_aft_unique.sort_values('rank').groupby(['after_site', 'device', 'keyword']).first()
getstat_aft_unique = getstat_aft_unique.reset_index()
getstat_aft_unique = getstat_aft_unique[getstat_aft_unique['after_site'] != '']
getstat_aft_unique = getstat_aft_unique.sort_values(['keyword', 'device', 'rank'])
getstat_aft_unique = getstat_aft_unique.rename(columns = {'rank': 'after_rank',
'result types for dec 17, 2020': 'after_snippets'})
getstat_aft_unique = getstat_aft_unique[['keyword', 'market', 'device', 'after_snippets', 'search_volume',
'after_url', 'after_site', 'after_rank'
]]
Segment The SERP Sites
When it comes to core updates, most of the answers tend to be in the SERPs. This is where we can see what sites are being rewarded and others that lose out.
With the datasets deduped and separated, we’ll work out the common competitors so we can start segmenting them manually which will help us visualize the impact of the update.
serps_before = getstat_bef_unique serps_after = getstat_aft_unique serps_before_after = serps_before_after.merge(serps_after, left_on = ['keyword', 'before_site', 'device', 'market', 'search_volume'], right_on = ['keyword', 'after_site', 'device', 'market', 'search_volume'], how = 'left')
Cleaning the rank columns of null (NAN Not a Number) values using the np.where() function which is the Panda’s equivalent of Excel’s if formula.
serps_before_after['before_rank'] = np.where(serps_before_after['before_rank'].isnull(), 100, serps_before_after['before_rank']) serps_before_after['after_rank'] = np.where(serps_before_after['after_rank'].isnull(), 100, serps_before_after['after_rank'])
Some calculated metrics to show the rank difference before vs after, and whether the URL changed.
serps_before_after['rank_diff'] = serps_before_after['before_rank'] - serps_before_after['after_rank'] serps_before_after['url_change'] = np.where(serps_before_after['before_url'] == serps_before_after['after_url'], 0, 1) serps_before_after['project'] = site_name serps_before_after['reach'] = 1 serps_before_after
 Screenshot by author, January 2022
Screenshot by author, January 2022Aggregate The Winning Sites
With the data cleaned, we can now aggregate to see which sites are the most dominant.
To do this, we define the function which calculates weighted average rank by search volume.
Not all keywords are as important which helps make the analysis more meaningful if you care about the keywords that get the most searches.
def wavg_rank(x):
names = {'wavg_rank': (x['before_rank'] * (x['search_volume'] + 0.1)).sum()/(x['search_volume'] + 0.1).sum()}
return pd.Series(names, index=['wavg_rank']).round(1)
rank_df = serps_before_after.groupby('before_site').apply(wavg_rank).reset_index()
reach_df = serps_before_after.groupby('before_site').agg({'reach': 'sum'}).sort_values('reach', ascending = False).reset_index()
commonstats_full_df = rank_df.merge(reach_df, on = 'before_site', how = 'left').sort_values('reach', ascending = False)
commonstats_df = commonstats_full_df.sort_values('reach', ascending = False).reset_index()
commonstats_df.head()
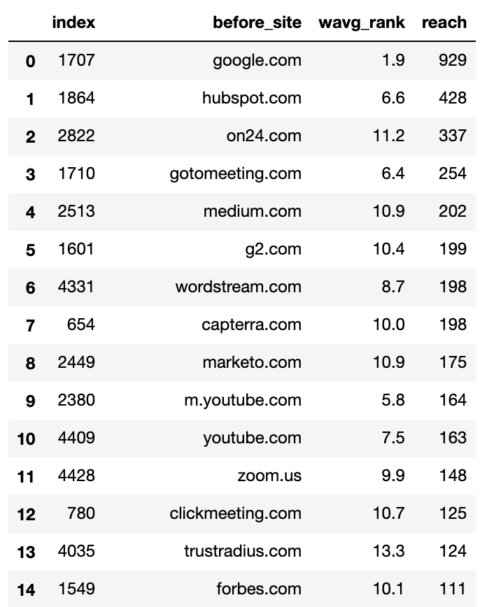 Screenshot by author, January 2022
Screenshot by author, January 2022While the weighted average rank is important, so is the reach as that tells us the breadth of the site’s presence in Google i.e. the number of keywords.
The reach also helps us prioritize the sites we want to include in our segmentation.
The segmentation works by using the np.select function which is like a mega nested Excel if formula.
First, we create a list of our conditions.
domain_conds = [ commonstats_df['before_site'].isin(['google.com', 'medium.com', 'forbes.com', 'en.m.wikipedia.org', 'hbr.org', 'en.wikipedia.org', 'smartinsights.com', 'mckinsey.com', 'techradar.com','searchenginejournal.com', 'cmswire.com']), commonstats_df['before_site'].isin(['on24.com', 'gotomeeting.com', 'marketo.com', 'zoom.us', 'livestorm.co', 'hubspot.com', 'drift.com', 'salesforce.com', 'clickmeeting.com', 'qualtrics.com', 'workcast.com', 'livewebinar.com', 'getresponse.com', 'superoffice.com', 'myownconference.com', 'info.workcast.com']), commonstats_df['before_site'].isin([ 'neilpatel.com', 'ventureharbour.com', 'wordstream.com', 'business.tutsplus.com', 'convinceandconvert.com']), commonstats_df['before_site'].isin(['trustradius.com', 'g2.com', 'capterra.com', 'softwareadvice.com', 'learn.g2.com']), commonstats_df['before_site'].isin(['youtube.com', 'm.youtube.com', 'facebook.com', 'linkedin.com', 'business.linkedin.com', ]) ]
Then we create a list of the values we want to assign for each condition.
segment_values = ['publisher', 'martech', 'consulting', 'reviews', 'social_media']
Then create a new column and use np.select to assign values to it using our lists as arguments.
commonstats_df['segment'] = np.select(domain_conds, segment_values, default="other") commonstats_df = commonstats_df[['before_site', 'segment', 'reach', 'wavg_rank']] commonstats_df
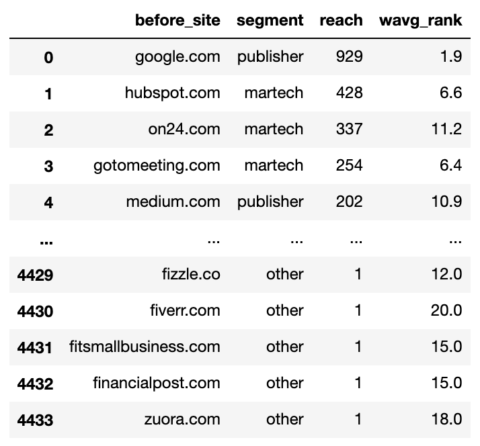 Screenshot by author, January 2022
Screenshot by author, January 2022The domains are now segmented which means we can start the fun of aggregating to see which site types benefitted and deteriorated from the update.
# SERPs Before and After Rank serps_stats = commonstats_df[['before_site', 'segment']] serps_segments = commonstats_df.segment.to_list()
We’re joining the unique before SERPs data with the SERP segments table created immediately above to segment the ranking URLs using the merge function.
The merge function that uses the ‘eft’ parameter is equivalent to the Excel vlookup or index match function.
serps_before_segmented = getstat_bef_unique.merge(serps_stats, on = 'before_site', how = 'left') serps_before_segmented = serps_before_segmented[~serps_before_segmented.segment.isnull()] serps_before_segmented = serps_before_segmented[['keyword', 'segment', 'device', 'search_volume', 'before_snippets', 'before_rank', 'before_url', 'before_site']] serps_before_segmented['count'] = 1 serps_queries = serps_before_segmented['keyword'].to_list() serps_queries = list(set(serps_queries)) serps_before_segmented
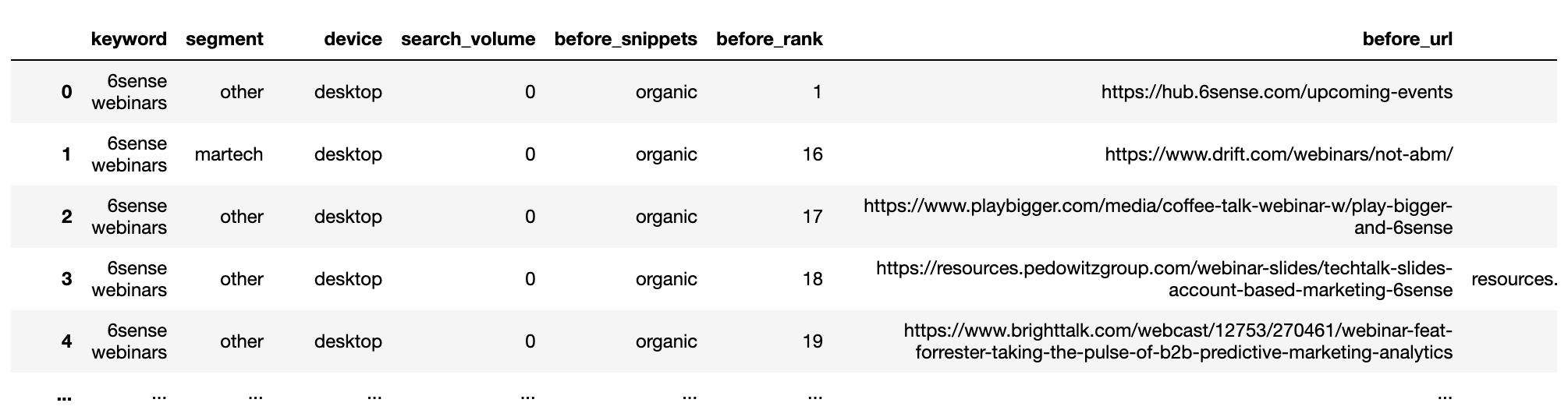 Screenshot by author, January 2022
Screenshot by author, January 2022Aggregating the before SERPs:
def wavg_rank_before(x):
names = {'wavg_rank_before': (x['before_rank'] * x['search_volume']).sum()/(x['search_volume']).sum()}
return pd.Series(names, index=['wavg_rank_before']).round(1)
serps_before_agg = serps_before_segmented
serps_before_wavg = serps_before_agg.groupby(['segment', 'device']).apply(wavg_rank_before).reset_index()
serps_before_sum = serps_before_agg.groupby(['segment', 'device']).agg({'count': 'sum'}).reset_index()
serps_before_stats = serps_before_wavg.merge(serps_before_sum, on = ['segment', 'device'], how = 'left')
serps_before_stats = serps_before_stats.rename(columns = {'count': 'before_n'})
serps_before_stats
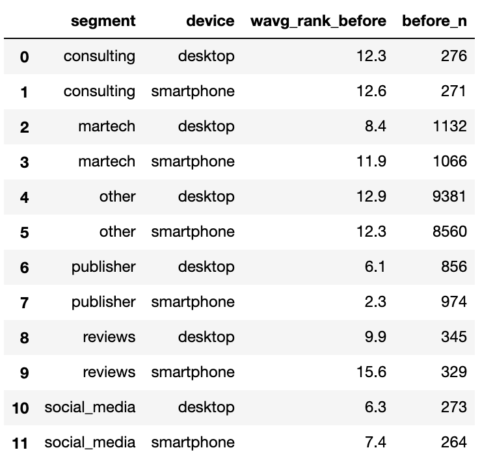 Screenshot by author, January 2022
Screenshot by author, January 2022Repeat procedure for the after SERPs.
# SERPs After Rank
aft_serps_segments = commonstats_df[['before_site', 'segment']]
aft_serps_segments = aft_serps_segments.rename(columns = {'before_site': 'after_site'})
serps_after_segmented = getstat_aft_unique.merge(aft_serps_segments, on = 'after_site', how = 'left')
serps_after_segmented = serps_after_segmented[~serps_after_segmented.segment.isnull()]
serps_after_segmented = serps_after_segmented[['keyword', 'segment', 'device', 'search_volume', 'after_snippets',
'after_rank', 'after_url', 'after_site']]
serps_after_segmented['count'] = 1
serps_queries = serps_after_segmented['keyword'].to_list()
serps_queries = list(set(serps_queries))
def wavg_rank_after(x):
names = {'wavg_rank_after': (x['after_rank'] * x['search_volume']).sum()/(x['search_volume']).sum()}
return pd.Series(names, index=['wavg_rank_after']).round(1)
serps_after_agg = serps_after_segmented
serps_after_wavg = serps_after_agg.groupby(['segment', 'device']).apply(wavg_rank_after).reset_index()
serps_after_sum = serps_after_agg.groupby(['segment', 'device']).agg({'count': 'sum'}).reset_index()
serps_after_stats = serps_after_wavg.merge(serps_after_sum, on = ['segment', 'device'], how = 'left')
serps_after_stats = serps_after_stats.rename(columns = {'count': 'after_n'})
serps_after_stats
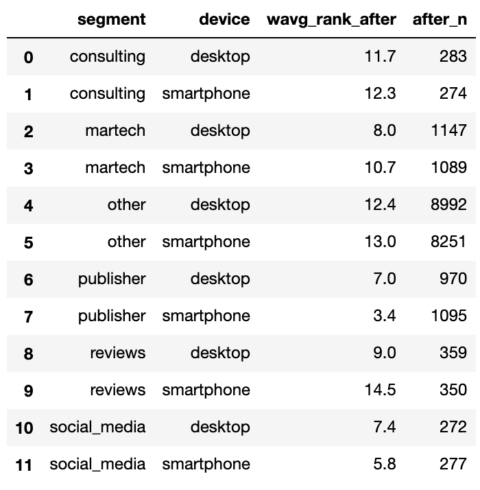 Screenshot by author, January 2022
Screenshot by author, January 2022With both SERPs summarised, we can join them and start making comparisons.
serps_compare_stats = serps_before_stats.merge(serps_after_stats, on = ['device', 'segment'], how = 'left') serps_compare_stats['wavg_rank_delta'] = serps_compare_stats['wavg_rank_after'] - serps_compare_stats['wavg_rank_before'] serps_compare_stats['sites_delta'] = serps_compare_stats['after_n'] - serps_compare_stats['before_n'] serps_compare_stats
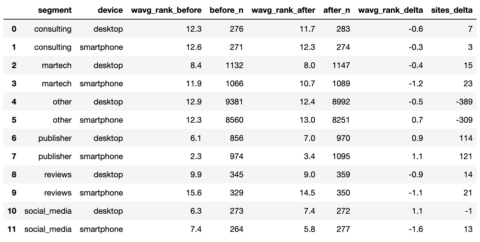 Screenshot by author, January 2022
Screenshot by author, January 2022Although we can see that publisher sites seemed to gain the most by virtue of more keywords ranked for, a picture would most certainly tell a 1000 more words in a PowerPoint deck.
We’ll endeavor to do this by reshaping the data into a long format that the Python graphics package ‘plotnine’ favors.
serps_compare_viz = serps_compare_stats
serps_rank_viz = serps_compare_viz[['device', 'segment', 'wavg_rank_before', 'wavg_rank_after']].reset_index()
serps_rank_viz = serps_rank_viz.rename(columns = {'wavg_rank_before': 'before', 'wavg_rank_after': 'after', })
serps_rank_viz = pd.melt(serps_rank_viz, id_vars=['device', 'segment'], value_vars=['before', 'after'],
var_name="phase", value_name="rank")
serps_rank_viz
serps_ba_plt = (
ggplot(serps_rank_viz, aes(x = 'segment', y = 'rank', colour="phase",
fill="phase")) +
geom_bar(stat="identity", alpha = 0.8, position = 'dodge') +
labs(y = 'Google Rank', x = 'phase') +
scale_y_reverse() +
theme(legend_position = 'right', axis_text_x=element_text(rotation=90, hjust=1)) +
facet_wrap('device')
)
serps_ba_plt
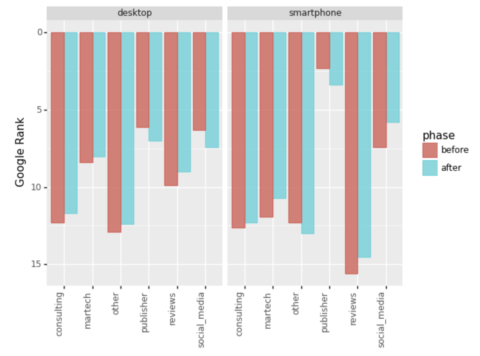 Screenshot by author, January 2022
Screenshot by author, January 2022And we have our first visualization, which shows us how most site types gained in ranking which is only half of the story.
Let’s also look at the number of entries into the top 20.
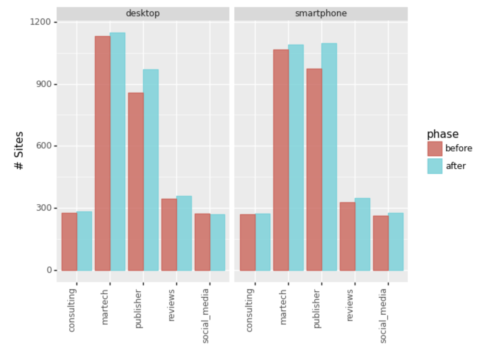 Screenshot by author, January 2022
Screenshot by author, January 2022Ignoring the ‘Other’ segment, we can see Martech and Publishers were the main winners expanding their keyword reach.
Summary
It took a bit of code just to create a single chart with all the cleaning and aggregating.
However, the principles can be applied to achieve extended winner-loser views such as:
- Domain level.
- Internal site content.
- Result Types.
- Cannibalised results.
- Ranking URL Content types (blogs, offer pages etc).
Most SERP reports will have the data to perform the above extended views.
While it might not explicitly reveal the key ranking factor, the views can tell you a lot about what is going on, help you explain the core update to your colleagues, and generate hypotheses to test if you’re one of the less lucky ones looking to recover.
More resources:
Featured Image: Pixels Hunter/Shutterstock